Introduction
You’ve probably heard the term “context engineering” or “memory architecture” in AI lately. And you might have thought “Oh it’s about how we’re building memory into language models.But memory isn’t being built into the LLM itself.It never will be at least not in the way you’re probably imagining. Instead memory architecture is about something fundamentally different it’s about the systems we build around a fundamentally stateless model to give it the appearance of memory.The moment an AI system is expected to behave consistently across multiple interactions whether it is a chatbot, a search assistant, a recommendation engine or an agent it must solve the same underlying problem.How to store, retrieve and apply past information.
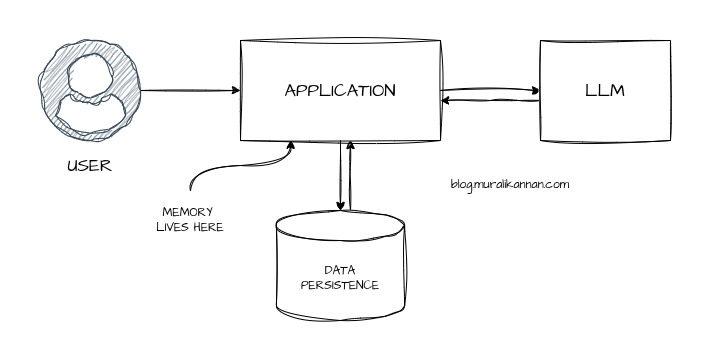
It is often framed as something specific to Agentic AI autonomous systems that plan, reason and act over time. While agents certainly make memory more visible memory itself is not an agent only concept.
In this post I will take you through the actual layers of how this works.Why LLMs are intentionally designed the way they are (stateless) and where the real “memory” lives in an AI system / application.
Before we begin let’s go through some of the myths regarding AI Memory
-
Myth : “LLM remembers me from last time”
Truth : Each API call is fresh. You have to pass history. -
Myth : “Memory is stored inside the neural network”
Truth : Memory is stored in external databases. The LLM has no persistent state. -
Myth : “Long context windows mean the AI has good memory”
Truth : Long context just means you can pass more tokens in one call. Still stateless. -
Myth : “Fine tuning is how we add knowledge to LLMs”
Truth : Fine-tuning updates weights (expensive, risky). Better to use retrieval + context. -
Myth : “RAG replaces memory”
Truth : RAG is one memory pattern. Works well for retrieval but not for temporal sequences or state. -
Myth : “We need bigger context windows to solve the memory problem”
Truth : Context windows helps but not the solution. Need better retrieval, compression and patterns.
The Context Window:
You might be thinking: “Wait I thought context windows were how LLMs remember things. Isn’t that memory?"
No. The context window is not memory. It’s something different.
A context window is the maximum number of tokens the model can process in a single API call.
GPT-4: up to 128,000 tokens in one call
Claude 3.5: up to 200,000 tokens in one call
Within that single call the model can “see” all those tokens and use them to predict the next one. That’s useful for processing long documents, code files or conversation history. But it’s not persistence.
Here’s the critical distinction:
Context Window works within single API Call. Memory works across API Calls.
When you hit the context window limit older information gets truncated and gone. The model never sees it.Now you may ask why Not Just Make Stateful LLMs? Why hasn’t someone just made an LLM that remembers things between calls?The answer is It’s not actually possible within the Transformer architecture without fundamentally changing how it works.
Transformer Architecture
The modern LLM is built on the Transformer architecture.Transformers process sequences in parallel not sequentially.Unlike older models (RNNs, LSTMs) that had hidden states that persisted as they processed text sequentially. Transformers on the other hand use something called self attention.
Consider the sentence:
“I left my phone on the table because it was slippery.”
When a Transformer processes this sentence it does not read it word by word.Instead it sees the entire sentence at once.
“it” looks at:
- “phone”
- “table”
- “slippery”
Based on context the model understands that “it” refers to the phone not the table.This happens because every word is allowed to look at every other word simultaneously using self attention.
What does not happen
There is no step where the model says
- I read “I left my phone…”
- I’ll remember this in my internal state
- Now I’ll process the next sentence using that memory
Once the sentence is processed the internal activations disappear.Transformers understand relationships within an input not across inputs.
Now let’s understand the need for memory.
Why Do We Need Memory ?
Imagine you’re talking to someone who has zero memory. Every single conversation they start fresh. No context. No history. No understanding of who you are.An LLM without memory is like a genius with amnesia.It can understand anything you tell it in the moment.But the moment the conversation ends that understanding disappears.It can’t build on previous knowledge.It can’t learn your preferences.It can’t understand your goals across multiple interactions.
Four Reasons Why Memory Is Essential
- Context Accumulation Over Time
- Personalization and User Understanding
- Consistency and Coherence
- Efficiency and Cost Optimization
Let’s take an example. where I am interacting with an LLm and making the LLM remember my name and conversation withing a single session during a multi turn conversation
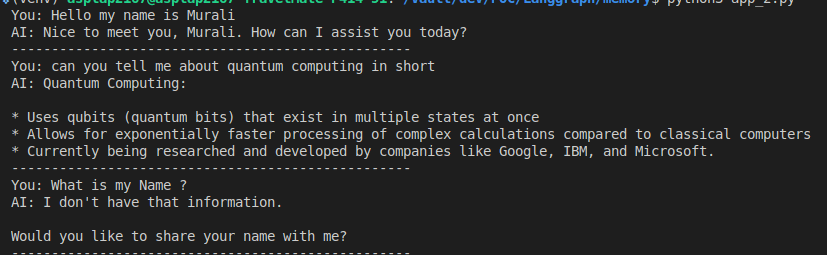
This is what an LLM without memory management looks like.Every API call is completely independent. Each response is generated without any context about previous conversations, preferences or what you’re trying to accomplish.So as expected the LLM has no idea who I am even though I had introduced me earlier during the conversation.
Now lets see an example with memory.
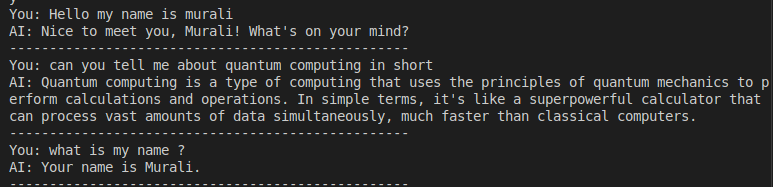
As you can see now when I introduced short term memory into the context the LLM could recall information I had passed on earlier during the conversation which in turn it remembers my name.
During each turn when the AI has context. It remembers what you’re building. It can give you tailored advice.
Memory transforms a stateless machine into something that can:
- Understand YOUR specific needs
- Build on PREVIOUS conversations
- Maintain CONSISTENCY over time
- ADAPT to your preferences
- SCALE with your projects
Without memory the LLM is powerful but brilliant at pattern matching but incapable of understanding context.With memory the system becomes intelligent not because the LLM changed but because the system around it gives the LLM the information it needs to be useful.
Designing Memory for modern AI Systems
Now let’s explore the hardships of designing a memory architecture. By Understanding why memory is necessary helps you make better architectural decisions wile builing context aware AI systems.
-
What to Store?
If done right : You store things that create context and personalization.
If done wrong : You might store everything or nothing or the wrong things. -
How to Retrieve?
If done right : You retrieve information that’s actually relevant to the current question.
If done wrong : You might retrieve everything (expensive) or nothing (unhelpful). -
When to Update Memory?
If done right : You update memory when you learn something new about the user/project/context.
If done wrong : You might update on every message (wasteful) or never (unhelpful). -
How Long to Keep It?
If done right : You keep long-term context that shapes decisions, and forget noise.
If done wrong : You might keep everything forever (bloat) or delete too aggressively (lost learning).
Regardless of the domain customer support, healthcare, finance, developer tools the core memory architecture remains remarkably consistent.The business logic changes but the layers do not.
At a high level most AI systems that support multi turn interactions follow the same pattern.
- A user sends an input to the system
- The application forwards the input to an LLM
- The LLM generates a response
- The application persists relevant parts of the interaction
- On the next interaction the application retrieves stored memory
- The system configures context by selecting what should and should not be included
- The user’s new query is combined with this context and sent to the LLM again
This separation gives us both power and responsibility.
Power: Because we can control what the model remembers. Responsibility: Because poor memory design leads to hallucinations, token bloat, latency and inconsistent behavior
Understanding memory types helps us design these systems intentionally rather than accidentally.
Common Types of Memory in AI Systems
While terminology varies across frameworks most modern AI systems implement some variation of the following memory categories.
- Short Term (Working) Memory
Short term memory is thread scoped.It captures recent messages within the current conversation or thread and is primarily used to maintain coherence across multiple turns.
Characteristics:
- Scoped to a single session or thread
- High relevance low longevity
- Often stored in memory, Redis or fast databases
- Typically injected verbatim or lightly summarized
Example:
Keeping track of what the user asked two or three messages ago so the assistant can respond naturally.This is the most expensive memory type in terms of tokens and must be aggressively curated.
- Long Term Memory
Long term memory captures cross interaction knowledge.It does not store every conversational detail but instead retains distilled information that remains useful across sessions.
Characteristics:
- User or entity scoped
- Extracted, summarized or embedded
- Retrieved selectively based on relevance
Often stored in vector databases or structured stores
Example:
Remembering that a user prefers concise answers or that a company uses a specific internal tool.Long term memory improves personalization and continuity without overwhelming the context window.
- Episodic Memory
Episodic memory represents meaningful past interactions as events.Instead of raw messages it stores higher level summaries of conversations, decisions or outcomes.
Characteristics:
- Event centric rather than message centric
- Time aware
- Often summarized and indexed
- Useful for reasoning over past experiences
Example:
“The user previously struggled with Kubernetes networking and requested step by step explanations.”
Episodic memory is especially valuable for agents that need to reflect, plan or adapt over time.
- Semantic Memory
Semantic memory stores facts and knowledge detached from specific conversations.Unlike episodic memory it is not tied to when or how the information was learned.
Characteristics:
- Fact based
- Stable over time
- Often normalized or structured
- Retrieved by relevance or query intent
Example:
“User works as a Doctor” or “This organization follows SOC-2 compliance.” Semantic memory supports reasoning without conversational baggage.
- Procedural / Behavioral Memory
This memory captures how the system should behave not what it should know. Characteristics:
- Rules, preferences or policies
- Often implemented as metadata or configuration
- Influences prompt structure and tool usage
Example:
Always explain trade offs before giving recommendations.Avoid overly verbose responses unless explicitly requested.This memory type is critical for consistency and alignment.
Demo Example
Now let’s program a 3 node agentic AI langgraph application to persist memory in a multi turn conversation.What I am trying to do here is crete a global memory state to persist multi turn conversation list and feed it into LLM as a context during each interaction and update the memory state in a dedicated memory node and handle the response in a dedicated response node.
I have kept 3 node for simplicity and understanding purpose a real world production grade system will have many nodes and complex edges.
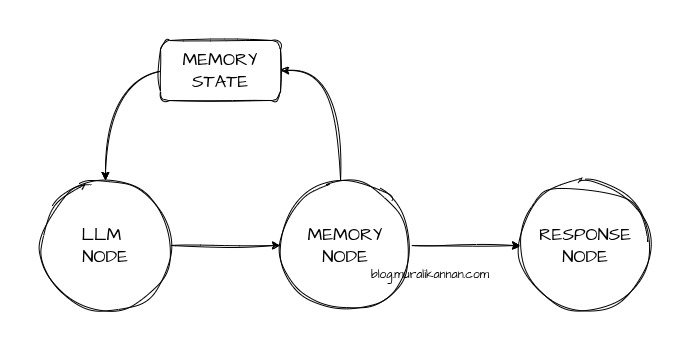
What it will give us is a good context (short term & long term memory) within the current conversation thread so the LLM has a bit more context on the conversation history so it can respond cohesively.
- First lets import the necessary type, langgraph & ollama connector (I am using my local Ollama instance running Llama for the demo you can use any API from OpenAI, Gemini, Claude, Bedrock etc..)
from typing import List, TypedDict
from langgraph.graph import StateGraph, END
from langchain_ollama import OllamaLLM
# Long-term memory
LONG_TERM_MEMORY: List[str] = []
- StateGraph is LangGraph’s execution engine
- END marks the termination of a graph run
- LONG_TERM_MEMORY is not part of LangGraph (It lives outside the graph)
- It survives & gets updated across invocations
Now lets declare a chatState
class ChatState(TypedDict):
messages: List[str]
- This is the entire working memory of the agent.
- messages contains everything the agent can “see”
- This state is passed between nodes & mutated by nodes
- discarded after execution (unless you persist it)
Next we are setting up Ollama connector for Ollama interaction
llm = OllamaLLM(model="llama3.1:latest")
Here we are declaring our LLM Node with chatState
def llm_node(state: ChatState) -> ChatState:
user_input = state["messages"][-1]
prompt = f"""
You are a helpful assistant.
Long-term memory:
{LONG_TERM_MEMORY}
Conversation so far:
{state["messages"]}
Reply concisely.
"""
response = llm.invoke(prompt)
return {
"messages": state["messages"] + [response]
}
This node
- Reads working memory (state[“messages”])
- Reads long-term memory (global variable)
- Calls the LLM
- Appends the response back into the working memory
What this node deliberately does NOT do
- It does not decide what to remember
- It does not write to long-term memory
Here we are declaring our memory node with chatState
def memory_node(state: ChatState) -> ChatState:
global LONG_TERM_MEMORY
user_input = state["messages"][-2]
if "my name is" in user_input.lower():
LONG_TERM_MEMORY.append(user_input)
return state
- This node exists only to manage memory.
- It Looks at what just happened
- Decides whether something is worth remembering (For demo purpose I have explicitly mentioned to remember the name but real world systems will have complex long term memory logic)
- Writes to long-term storage
Now lets declare our response node with chatState
def response_node(state: ChatState) -> ChatState:
return state
- It represents the end of reasoning & clean boundary before returning output
We can also add a conditional node to skip memory if required
def route_after_llm(state: ChatState):
return "memory"
- This function decides what happens after reasoning.
- In this simplified demo we always route to memory
- But this is where ephemeral vs persistent behavior is controlled
Now lets build the Langgraph Graph with nodes and edges
graph = StateGraph(ChatState)
graph.add_node("llm", llm_node)
graph.add_node("memory", memory_node)
graph.add_node("response", response_node)
graph.set_entry_point("llm")
graph.add_conditional_edges(
"llm",
route_after_llm,
{
"memory": "memory",
"response": "response",
},
)
graph.add_edge("memory", "response")
graph.add_edge("response", END)
chat_app = graph.compile()
- Initializes a state driven execution graph using ChatState as the shared working memory
- Registers three distinct nodes each with a single responsibility (llm, memory & response)
- Sets llm node as the entry point
- Adds conditional edges from the llm node using route_after_llm (This makes memory optional not implicit)
- If routed to memory the graph executes persistence logic then continues to response
- If memory is skipped the graph never touches persistence logic at all (Memory exists only because there is a path to it)
- The response node always leads to END
- Ensures a single predictable termination point
- no accidental re execution or looping
- clean separation between reasoning and output
Now lets create a main function to take user input and invoke our langgraph
def run_chat():
state: ChatState = {"messages": []}
while True:
user_input = input("You: ").strip()
if user_input.lower() == "exit":
print("\nGoodbye")
break
# Append user message
state["messages"].append(user_input)
state = chat_app.invoke(state)
print("AI:", state["messages"][-1])
print("-" * 50)
if __name__ == "__main__":
run_chat()
- Initializes an empty ChatState, representing the agent’s working memory.
- Continuously reads user input from the CLI until exit is typed.
- Appends each user message to the working memory (state[“messages”]).
- Invokes the LangGraph execution with the current state.
- Receives an updated state after graph execution.
- Prints the latest LLM response from the state.
After this our conversation shoud feel natural since our past conversation data is fed as a context during each interaction and LLM should remember relavant cues from the history.
This is just an example to understand the memory concept.In real production systems the memory goes through a lot of optimizations and we have to be mindful about the token usage as well!!
Conclusion
As we have seen memory is an integral part in designing stateful AI systems which can cohesively respond to user interactions.Modern LLMs are powerful not because they remember but because they reason extremely well over the context they are given. The Transformer architecture enables rich understanding within an input yet it remains fundamentally stateless across interactions.As a result memory is not an inherent property of the model it is an architectural responsibility of the surrounding system.
Whether we are building a simple chatbot or a fully agentic system the core challenge is the same deciding what to remember, how to store it and when to reintroduce it into the model’s context. Agentic AI systems make this challenge more visible but they do not change its nature. Memory at its core is a system level design problem and treating it as such is essential for building reliable, predictable AI applications.
Citations
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
https://arxiv.org/abs/1706.03762
https://arxiv.org/abs/2404.07143
https://langchain-ai.github.io/langgraph/concepts/memory/
https://arxiv.org/abs/2501.13956
https://docs.langchain.com/oss/python/langgraph/memory
https://blog.langchain.com/launching-long-term-memory-support-in-langgraph/
Image Courtesy : Generated using AI (GPT 5.2)