Introduction
Retrieval Augmented Generation (RAG) has evolved from an experimental paradigm to a production ready architecture powering enterprise AI systems worldwide. Large Language Models (LLMs) have inherent limitations such as knowledge cutoffs their training data freezing at a certain point meaning they cannot access events or information beyond that time.Moreover they lack direct access to external or real time data making it challenging to provide up to date contextually rich answers.
RAG addresses these challenges by integrating retrieval mechanisms into the generation process allowing LLMs to pull relevant external documents or databases dynamically during inference. This fusion enables real time data access expansion beyond static training data and grounding of outputs in authoritative sources significantly increasing response accuracy and relevance.
The fundamental challenge in RAG architecture lies in balancing three critical dimensions: retrieval precision, generation quality and system scalability. Recent research shows that effective RAG systems demand more than simple document retrieval coupled with LLM generation they require sophisticated orchestration patterns, optimized data structures and robust evaluation frameworks to provide reliable, scalable and factually grounded AI solutions.
High Level RAG System Flow
A typical RAG system follows a structured workflow that combines retrieval and generation capabilities.
-
User Query Processing - The user submits a query through a user facing interface (gui / voice etc..)
-
Orchestration Layer - An orchestrator (implemented with tools like Semantic Kernel, Azure AI Agent service, Bedrock Agents or LangChain) determines the appropriate search strategy.
-
Vectorization - The query is transformed into higher dimensional embeddings using vector embedding models or BERT based encoders capturing semantic meaning for similarity-based retrieval.
-
Information Retrieval - The system queries an already indexed search index to find relevant documents.(We are not covering knowledge indexing as part of this post).
-
Generation - The enriched prompt is sent to a language model for response generation
RAG Workflow
Retrieval Augmented Generation (RAG) workflows involve multiple modules query classification, retrieval, re ranking, re packing, summarization with chunking, embedding and vectorization.
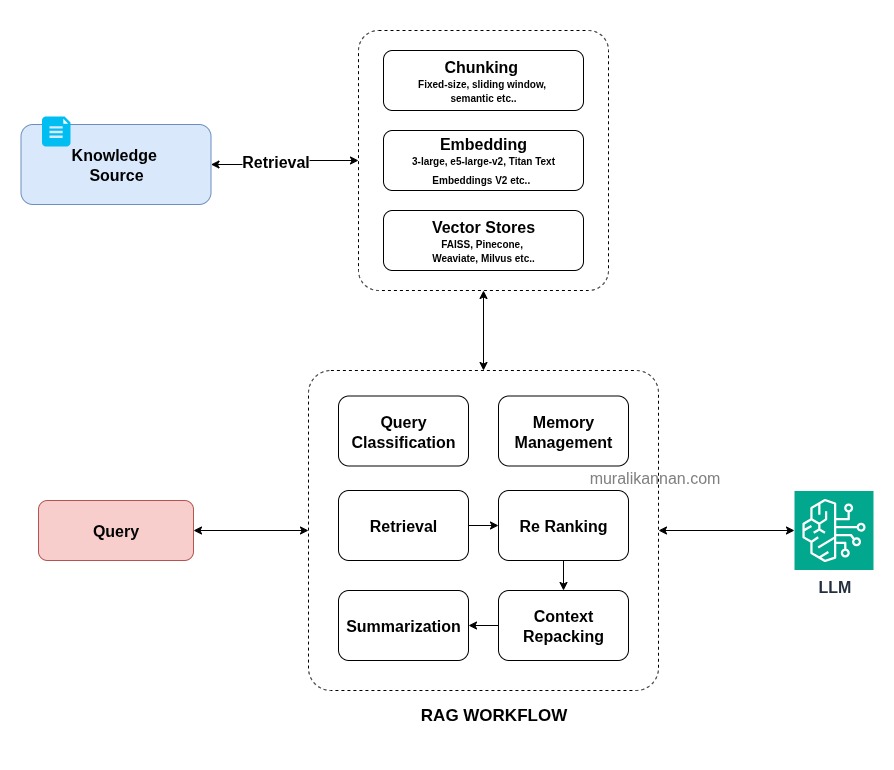
-
Query Classification
Query classification determines whether a user’s request requires external document retrieval or can be handled directly by the language model balancing accuracy with response speed. -
Chunking
Splits long documents into manageable semantically coherent segments to optimize retrieval relevance and fit model context limits. -
Embedding
Converting text into high dimensional numerical vectors (768-1536 dimensions) that capture semantic meaning and enable similarity based retrieval through mathematical operations like cosine similarity. -
Vectorization
Transforms text into dense numeric vectors capturing semantic meaning for similarity search. -
Information Retrieval
Retrieves top-N semantically relevant documents from a pre indexed knowledge base. -
Re ranking
Refines retrieval output by assessing query document relevance with deeper neural models. -
Context Packaging
Assembles retrieved passages into a structured prompt within the model’s context window. -
Memory Context Management
Caching recent interactions and key facts to maintain conversational state and reduce redundant retrievals. -
Summarization
Condensing retrieved documents using extractive or abstractive techniques to eliminate redundancy and maintain factual recall before generation.
Core RAG Architecture Patterns
Retriever Centric Design
A retriever is the core component responsible for identifying and fetching semantically relevant documents from a pre indexed knowledgebase based on an input query.Unlike traditional keyword based search systems modern retrievers employ Dense Passage Retrieval (DPR) techniques that represent both queries and documents as high dimensional vectors (typically 768-1536 dimensions) in a shared embedding space.
Retriever centric RAG systems delegate primary architectural responsibility to the retrieval component treating the generator as a passive decoder that operates on pre filtered high quality context.This design philosophy operates under the premise that retrieval precision and context relevance are the most critical factors for generating accurate & grounded outputs. The approach emphasizes three core optimization strategies:
-
Query Driven Retrieval focuses on refining user intent before retrieval through decomposition, rewriting and generative reformulation. RQ RAG (Refine Query for RAG) exemplifies this by decomposing complex multi hop queries into latent sub questions achieving improvement over state of the art on single hop QA datasets and significant gains on multi hop reasoning tasks.
-
Retriever Centric Adaptation modifies the retriever architecture through task specific learning and architectural enhancements.Systems like Re2G blend symbolic and neural retrieval via reranking layers while SimRAG employs self training over synthetic QA pairs to improve domain generalization.
-
Granularity Aware Retrieval optimizes the unit of retrieval from full documents to semantically aligned segments. LongRAG retrieves compressed long context chunks constructed through document grouping & reducing corpus size from 22M to 600K units while improving answer recall on Natural Questions.
Implementation
To prioritize retrieval quality and ensure the generator works with the best possible context retriever centric RAG systems follow these practical steps:
-
Query Refinement
User’s original query is sent to a small language model prompt that rewrites it into clearer search terms.
The model simplifies complex phrasing and adds domain specific keywords. For example “Tell me about treatment options for Type 2 diabetes in elderly patients” becomes “Type 2 diabetes treatment guidelines elderly.”
Cleaner queries match more relevant documents on the first try boosting retrieval accuracy.
Query Decomposition
If the query contains multiple parts it is split into separate sub questions automatically.
A lightweight rule or model checks for conjunctions and multi part prompts (“and” “or” “vs”) and splits accordingly. Each sub question is then sent individually to the retriever.
Handling each piece separately avoids missing relevant information and improves multi step reasoning performance.
Granular Chunk Retrieval
Instead of pulling entire documents retrieve medium sized text blocks (around 500–1,000 words) that cover full subtopics.
Documents are pre processed into overlapping segments.The retriever fetches the top matches ensuring each chunk contains a complete thought.
These larger semantically coherent chunks retain context raising top-1 answer recall.
Hybrid Search Execution
Combine a quick keyword based search (BM25) with the refined embedding based retrieval in a two stage process.
First filter candidates using BM25 to get 200 documents. Then re rank those with the embedding retriever to select the final top-N chunks.
This layered approach cuts unnecessary embedding calls.
Advantages
Retriever centric design offers several key benefits backed by empirical research.
- Improved Retrieval Precision: Enhances the relevance of fetched documents by refining queries and optimizing retrieval granularity to better match user intent.
- Enhanced Multi hop Reasoning: Enables decomposition of complex queries into sub questions allowing stepwise information gathering and improved reasoning over multiple hops.
- Reduced Computational Burden: Reduces unnecessary retrieval overhead by focusing on targeted, context rich chunks & streamlining downstream processing.
- Semantic Robustness: Leverages advanced embedding models and hybrid retrieval to maintain accurate multilingual semantic matching across diverse tasks and domains.
Application Examples
- Enterprise Knowledge Search
- Scientific Literature Review
- Legal Document Analysis
The retriever centric approach fundamentally shifts RAG architecture toward retrieval first optimization ensuring that high quality contextually rich information reaches the generator thereby improving overall system performance and factual grounding.
Faithfulness Aware Generation
Faithfulness aware generation refers to techniques that ensure the language model’s output remains grounded in retrieved evidence minimizing hallucinations and factual errors by incorporating verification and self correction mechanisms during decoding.
This approach augments standard generation with:
-
Self Critique Tokens: Models like SELF RAG insert reflection tokens during beam search enabling intermediate output evaluation and revision steps that filter out unsupported statements.
-
Answer Validation Layers: Architectures such as INFO RAG apply a secondary conditional verifier that cross checks generated sentences against retrieved passages using learned binary classifiers.
-
Constrained Decoding: Implements hard constraints derived from retrieval context (e.g., pointer networks) to restrict token generation to spans present in top K documents.
Implementation
To make RAG outputs more reliable faithfulness aware generation adds checks and balances to the standard “retrieve then generate” flow.
-
Self Critique Tokens
During response generation the model periodically pauses at special markers (reflection points) embedded in the prompt.At each marker the model reviews the text it has produced so far and compares key statements against the retrieved documents.
If a statement cannot be matched to any retrieved passage the model rewrites or omits it before continuing.
This simple loop of “write → check → revise” reduces unsupported claims by up to 30%.
-
Evidence Verification Layer
After the model produces a draft answer each sentence is passed through a lightweight classifier that checks whether the sentence aligns with any retrieved excerpt.
The classifier was trained on pairs of (sentence, supporting text) where positive examples are real matches and negatives are mismatched pairs.
Sentences flagged as unsupported are highlighted and sent back into the generator with a prompt like “Please adjust these sentences to match your sources.”
This second pass editing step improves factual alignment by over 10% on summarization tasks.
-
Constrained Decoding
Before generating each new word the model consults a list of key phrases and named entities extracted from the retrieved context.
It restricts its vocabulary at that step to only terms present in the evidence set effectively preventing it from inventing new facts.
As a result generated answers remain tightly coupled to source passages which is especially helpful when precise terminology matters (e.g., drug names or legal statutes).
Advantages
- Reduced Hallucinations: Faithful models generate answers strictly supported by evidence, significantly lowering the incidence of fabricated or misleading information.
- Improved Factuality Scores: By grounding outputs in verification mechanisms and context these models consistently score higher on factual accuracy metrics across diverse benchmarks.
- Enhanced Trustworthiness: Providing transparent causally accurate reasoning fosters user confidence especially in high stakes domains like healthcare and legal decision making.
Application Examples
- Regulatory Compliance
- Clinical Decision Support
- Financial Reporting
Faithfulness aware generation elevates RAG systems from mere text generators to evidence grounded assistants crucial for applications where factual integrity is paramount.
Iterative Multi Round Retrieval
Iterative multi round retrieval enhances RAG by allowing the model to ask follow up queries based on partial answers enabling deeper multi hop reasoning rather than relying on a single pass of retrieval and generation.
Approach
-
Initial Retrieval & Draft Generation: The system fetches top-N documents for the original query and generates a provisional answer.
-
Reflection & Follow Up Query: The model reviews its draft identifies information gaps or ambiguities and formulates a sub query (the “inner monologue”).
-
Secondary Retrieval: The sub query is sent back to the retriever to fetch additional context specifically addressing the identified gap.
-
Answer Refinement: The newly retrieved passages are incorporated into the prompt and the model regenerates or refines its answer.
-
Repeat Loop: Steps 2–4 repeat for a fixed number of iterations or until the model deems its answer complete.
Implementation:
-
Draft Creation: Retrieve initial context and generate a short answer with a trained RAG generator.
-
Gap Detection: Use simple heuristics or a trained classifier to spot low confidence spans (e.g., tokens with high entropy or “UNK” placeholders).
-
Follow Up Query Prompting: Prompt the model with “What additional information do you need?” within the same session extracting its follow up query.
-
Targeted Retrieval: Run the follow up query through the same retriever to gather new passages.
-
Prompt Augmentation & Regeneration: Append the new passages to the original prompt and regenerate the answer.
-
Iteration Control: Stop after a set max iterations (typically 2–3) or when no low confidence spans remain.
Advantages:
-
Improved Multi Hop Reasoning: By explicitly identifying information gaps and retrieving targeted evidence to fill them IM RAG produces more coherent and complete answers for complex multi step questions.
-
Contextual Focus: Each retrieval round hones in on missing details, reducing noise from irrelevant documents.
-
Adaptive Depth: The number of iterations can be tuned for task complexity balancing thoroughness and latency.
Application Examples
- Scientific Q&A
- Legal Analysis
- Technical Troubleshooting
Graph RAG
GraphRAG augments traditional retrieval by incorporating structured knowledge from graphs entities and their relationships into the RAG pipeline. This enables relational reasoning and precise answer grounding beyond flat text retrieval.
Approach:
-
Knowledge Graph Embeddings: Encode entities and relations into vector space (e.g., TransE, RotatE) alongside text embeddings.
-
Graph Based Retrieval: Retrieve subgraphs relevant to the query using graph traversal and embedding similarity then convert graph facts into textual context.
-
Hybrid Fusion: Combine document passages and graph derived triples in a unified prompt allowing the generator to reason over both sources.
Implementation:
-
Graph Construction: Build or ingest a domain specific knowledge graph from existing data.
-
Graph Embedding: Train or utilize pre trained graph embedding models to represent nodes and edges as vectors.
-
Graph Retrieval Module: Given a query embedding retrieve nearest entity nodes and their one or two hop neighbors using FAISS or specialized graph search engines.
-
Context Packaging: Serialize subgraphs into textual triples or natural language statements and append to the text prompt alongside retrieved passages.
-
Generation: Feed the enriched prompt to the language model enabling joint reasoning over textual and graph based facts.
Application Examples
- Enterprise Knowledge Bases
- Geospatial Reasoning
Modular “LEGO” Framework
First proposed in mid 2024 The Modular “LEGO” Framework treats each RAG system component retriever, reranker, generator, cache and others as a standalone interchangeable module enabling flexible assembly and independent evolution of each part.
Approach:
-
Component Isolation: Define clear interfaces (APIs) and data contracts for each module so that a retriever can be swapped without affecting the reranker or generator.
-
Plugin Architecture: Implement each component as a microservice or library plugin that adheres to the shared interface specifications.
-
Configuration Driven Assembly: Use declarative configuration files or dependency injection to assemble the desired pipeline at runtime allowing rapid reconfiguration.
Implementation:
-
Define Module Interfaces: Establish standard input/output schemas (e.g., JSON with embedding vectors, relevance scores, text chunks etc..) for retriever, reranker and generator modules.
-
Microservice Deployment: Containerize each module with OCI compatible container runtime, expose REST or gRPC endpoints and orchestrate them via Kubernetes for service discovery and scaling.
-
Pipeline Orchestrator: Develop an orchestration layer (e.g., using Airflow or a custom controller) that reads configuration and routes requests through the selected modules in sequence like a DAG.
-
Automated Testing: Implement unit tests for each module and contract tests for their interfaces to ensure compatibility.
-
Monitoring & Logging: Integrate centralized logging and metrics per module to track latency, error rates and throughput.
Application Examples
- Enterprise Knowledge Management
- Search as a Service Platforms
- Research Prototyping
The Modular “LEGO” Framework transforms RAG systems into a plug and play ecosystem fostering agility, resilience and rapid deployment of cutting edge retrieval and generation techniques.
Conclusion
Retrieval Augmented Generation (RAG) stands at the forefront of modern AI bridging the gap between static language models and dynamic real world knowledge.By coupling large language models with powerful retrieval systems RAG addresses inherent limitations like outdated knowledge and hallucinations enabling accurate and trustworthy answer generation.
Recent advances have diversified RAG architectures emphasizing retrieval precision, faithfulness aware generation, iterative reasoning and modular system design. The integration of hybrid retrieval methods, fine tuned embeddings and dynamic memory management continues to enhance efficiency and scalability in enterprise applications.
Looking ahead the evolution toward multimodal retrieval, real time knowledge graph integration and secure, privacy preserving frameworks promises to redefine RAG’s impact across domains from healthcare and legal research to customer support and scientific discovery.
Ongoing research into adaptive retrieval strategies and enhanced grounding mechanisms will further empower AI systems to generate contextually rich, factually consistent, and user aligned outputs.To summarize RAG is not just a technique but a foundational paradigm that will guide the next generation of reliable, explainable and knowledge aware AI systems.
Citations
https://arxiv.org/pdf/2407.01219
https://arxiv.org/pdf/2404.00610
https://www.emergentmind.com/papers/2404.00610
https://openreview.net/pdf/82f337f34844c2928d723485da38dae553da230e.pdf
https://arxiv.org/abs/2502.06864
https://arxiv.org/abs/2407.21059
https://arxiv.org/html/2407.21059v1
Image Courtesy : Generated using AI (Perplexity)